momura
2018年4月19日 11時17分
大村と申します。Armadillo-X1にてSPI通信を行ないDMAにてメモリに読込みたいと考えております。
https://users.atmark-techno.com/blog/615/2577 ブログの方法で、SPI通信を成功させるところまでは
できました。
ここからが問題です。下記2点についてお伺いしたく、ご指導をお願い申し上げます。
① https://armadillo.atmark-techno.com/forum/armadillo/2648 フォーラムを見て
DMA転送を行なおうとしておりますが、初心者の私にはついていけない部分があります。
ecspi4の場合、先のブログで使用したarmadillo_x1-ecspi4_user1.dtsに下記2行を追加して、DTBを書き換えれば
DMA転送が開始されるだろうということは判りました。(もしこの理解が間違っていたらご指摘ください)
dmas = <&sdma 6 7 1>, <&sdma 7 7 2> /* ADD */
dma-names = "rx", "tx" /* ADD */
この後の手順がよく分かりません。ユーザーランドのアプリケーションで、DMA転送されたメモリ上のデータ
は何処を参照して、使用すればよいのか、ご指導をお願い致します。
サンプルソフトのようなものがあれば有り難く、何卒よろしくお願い申し上げます。
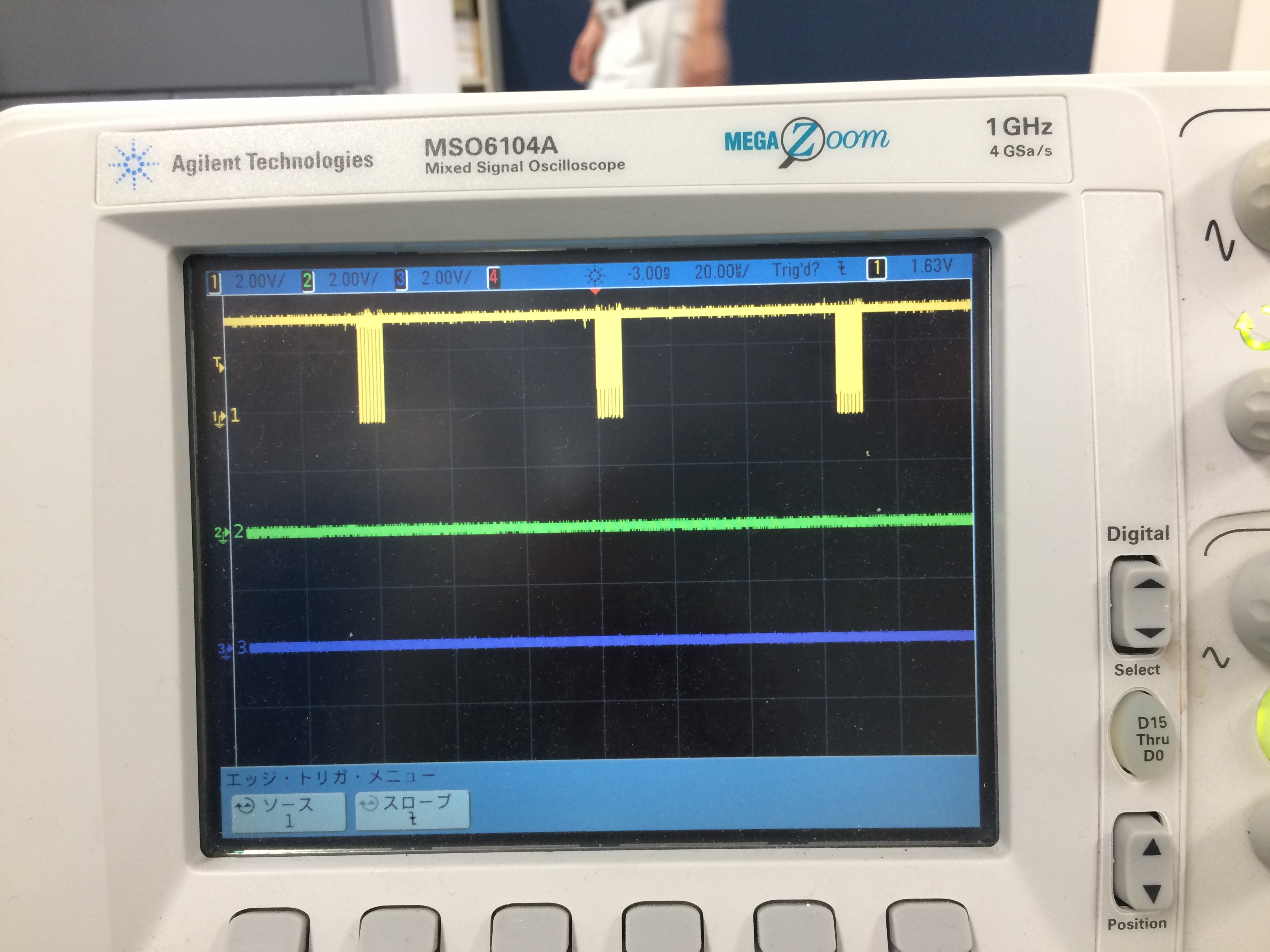
②SPIにて外部から受信し、30Mbpsの速度が出ていることは確認できました。
添付画像はそのときのSCLK端子の波形です。1回あたり7バイトのデータを連続して読込んでおりますが、
各回の間に60μs近い間隔が空いてしまい、高速化できません。
この間隔時間を短くする方法はないでしょうか? おそらくユーザーランドだけでは無理だと思われますが、
方法をご指導お願い申し上げます。
| ファイル | ファイルの説明 |
|---|---|
| 2018-04-16 19.49.23.jpg | SCLK端子波形 |
{kind=link}
コメント
momura
溝渕様
早速のご回答ありがとうございます。
> データの読込みはどのように行っていますか。
>
→
基本的に、ご紹介いただいた
「Armadillo実践開発ガイド第3部」
の方法をベースにしています。ioctl()の部分だけ、ループさせています。
関係ありそうな部分のソースの抜粋をお送りします。もちろんDMAは使用しておりません。
#define SPI_RCVMAX 1000000
#define SPI_RCVNUM 7
uint8_t tx[7] = {0, }; //ここを変更すると取り込みデータ数が変わる
uint8_t rx[7] = {0, };
spifd = fpga_open(); //SPI open
tx[0] = 0x00;
tx[1] = 0x00;
/* 転送設定をセットする */
tr.tx_buf = (unsigned long)tx;
tr.rx_buf = (unsigned long)rx;
tr.len = ARRAY_SIZE(tx);
tr.delay_usecs = FPGA_SPI_DELAY_USECS;
tr.speed_hz = FPGA_SPI_SPEED_HZ;
tr.bits_per_word = FPGA_SPI_BITS;
tr.cs_change = 0;
for(SPI_RcvPtr = 0; SPI_RcvPtr <= SPI_RCVMAX-1; SPI_RcvPtr++)
{
/* 全二重通信をおこなう */
ret = ioctl(spifd, SPI_IOC_MESSAGE(1), &tr);
/* 受信バッファから結果を取り出す */
for (i=0; i < SPI_RCVNUM; i++)
{
SPI_RcvBuf[SPI_RcvPtr][i] = (unsigned char)(rx[i]&0xff);
}
}
return fpga_close(); //SPI close
順番前後しますが、
>まず、DMAは、ECSPIのFIFOとメモリ間で行なわれます。DMAを利用しない場合
>は、FIFOアクセスはCPUが行います。そのため、DMAしてもしなくてもユーザー
>ランドからのアクセス方法にも違いはありません。
→
DMAを使用しても、上記の方法で読み出せるということでしょうか?
以上、取り急ぎご連絡申し上げます。 引き続き何卒よろしくお願い申し上げます。
at_mizo
momura
at_mizo
momura
溝渕様
> > この"dmas"プロパティを追加さえすれば、あとの部分は変えなくても
> > DMAが使用され高速になるということでしょうか?
>
> まず、「DMAが使用される」=「高速になる」は必ずしも成立しません。
>
> CPU性能が(dma対象のデバイスの通信速度に対して)低いまたは、CPU使用率が
> (FIFOアクセスを十分にできない程に)高い場合は概ね高速になると思います。
>
> 60usの間隔の原因がDMA未使用であることを疑っているのであれば、"dmas"プ
> ロパティを追加して挙動を確認するのは問題の切り分けとして適切だと思いま
> す。
>
→ 承知しました。まず、下記2行を追加することのみ行なって試してみます。
ありがとうございます。
dmas = <&sdma 6 7 1>, <&sdma 7 7 2> /* ADD */
dma-names = "rx", "tx" /* ADD */
momura
溝渕様
お世話になります。
> > この"dmas"プロパティを追加さえすれば、あとの部分は変えなくても
> > DMAが使用され高速になるということでしょうか?
>
> まず、「DMAが使用される」=「高速になる」は必ずしも成立しません。
>
> CPU性能が(dma対象のデバイスの通信速度に対して)低いまたは、CPU使用率が
> (FIFOアクセスを十分にできない程に)高い場合は概ね高速になると思います。
>
> 60usの間隔の原因がDMA未使用であることを疑っているのであれば、"dmas"プ
> ロパティを追加して挙動を確認するのは問題の切り分けとして適切だと思いま
> す。
→
dmasプロパティを追加してデバイスツリーを書き換えて試してみましたが
結果、処理速度が上がったようには見受けられませんでした。
約60μsの間隔も短くなったようには見受けられません。
DMAが動作しているかどうかは、どうすれば判断できるのでしょうか?
素人な質問ですみません。
at_mizo
溝渕です。
> dmasプロパティを追加してデバイスツリーを書き換えて試してみましたが
> 結果、処理速度が上がったようには見受けられませんでした。
先に書きましたが、DMAを利用しても多くの場合は高速化されないと思います。
> 約60μsの間隔も短くなったようには見受けられません。
古賀様がおっしゃっている通り、システムコール(ioctl)を複数回呼び出して
いるのは解消しましたか?
> DMAが動作しているかどうかは、どうすれば判断できるのでしょうか?
"/proc/interrupts"を読み出して、sdmaの割り込みが入っていることを確認す
ると良いと思います。
momura
溝渕様
回答ありがとうございます。
出張であったため、回答が遅くなりました。
> 先に書きましたが、DMAを利用しても多くの場合は高速化されないと思います。
そうなのですね。勉強になりました。
> 古賀様がおっしゃっている通り、システムコール(ioctl)を複数回呼び出して
> いるのは解消しましたか?
>
古賀様が詳しく解説してくださったので、それにトライしてみます。
> > DMAが動作しているかどうかは、どうすれば判断できるのでしょうか?
>
> "/proc/interrupts"を読み出して、sdmaの割り込みが入っていることを確認す
> ると良いと思います。
ありがとうございます。 まずDMAが動いているか確認してみます。
御礼もうしあげます。
momura
溝渕様
大村です。すみません。くどいようですが、もう1点確認させてください。
> まず、「DMAが使用される」=「高速になる」は必ずしも成立しません。
>
> CPU性能が(dma対象のデバイスの通信速度に対して)低いまたは、CPU使用率が
> (FIFOアクセスを十分にできない程に)高い場合は概ね高速になると思います。
→
私がDMAを使うと高速になると思っていたのは、SPI(FIFO)からメモリへの書き込みをCPUが介在せずに
行なうことができ、その間にCPUは別のことができると思っていたからです。
今回の案件では、SPIから取り込んだデータを最終的にUSBメモリに書き込む処理があります。
例えば、マルチスレッドにして、SPIから読込む処理と、USBメモリに書き込む処理をスレッドを分けて、
SPIからのデータをDMA転送で読込み、その間CPUはUSBメモリに書き込むといったようなことはできないのでしょうか?
linuxはリアルタイムOSではないので、限界があるのは分かっています。
しかし、せっかくDMAがあるのでうまく利用する方法はないのかなあと思ってしまいます。
分っている方には、思い違いしていると思われるかもしれませんが、確認させてください。
よろしくお願い申し上げます。
at_mizo
溝渕です。
> 私がDMAを使うと高速になると思っていたのは、SPI(FIFO)からメモリへの書き込みをCPUが介在せずに
> 行なうことができ、その間にCPUは別のことができると思っていたからです。
上記の場合、少なくともCPUが行っている仕事は、
1. SPI(FIFO)からメモリへの書き込み
2. 別のこと
の2つがあります。
"1."と"2."の合計で、CPUを100%使うのであれば、いずれか一方または両方が
遅くなります。この場合は、大抵の場合でDMAを利用することで高速化されます。
> 今回の案件では、SPIから取り込んだデータを最終的にUSBメモリに書き込む処理があります。
> 例えば、マルチスレッドにして、SPIから読込む処理と、USBメモリに書き込む処理をスレッドを分けて、
> SPIからのデータをDMA転送で読込み、その間CPUはUSBメモリに書き込むといったようなことはできないのでしょうか?
そもそもLinuxはマルチタスクなので、(厳密には同時ではありませんが)同時
に複数処理を行うことができます。DMAを使っているかどうかには関りません。
SPIとUSBを同時に利用できないのでしょうか?
> しかし、せっかくDMAがあるのでうまく利用する方法はないのかなあと思ってしまいます。
あえてCPUを使ってSPI(FIFO)からメモリへの書き込みを行う必要が無ければ、
(CPU利用率低減等を目的として)DMAを利用した方が良いように思います。
momura
溝渕様
ご回答ありがとうございます。すみません。返事が遅くなりました。
> 上記の場合、少なくともCPUが行っている仕事は、
> 1. SPI(FIFO)からメモリへの書き込み
> 2. 別のこと
> の2つがあります。
>
> "1."と"2."の合計で、CPUを100%使うのであれば、いずれか一方または両方が
> 遅くなります。この場合は、大抵の場合でDMAを利用することで高速化されます。
→
この点はよく理解できます。
> そもそもLinuxはマルチタスクなので、(厳密には同時ではありませんが)同時
> に複数処理を行うことができます。DMAを使っているかどうかには関りません。
>
> SPIとUSBを同時に利用できないのでしょうか?
> あえてCPUを使ってSPI(FIFO)からメモリへの書き込みを行う必要が無ければ、
> (CPU利用率低減等を目的として)DMAを利用した方が良いように思います。
→
ということは、やり方次第で、DMAをうまく利用して処理速度を上げることは可能ということですね。
承知しました。 私もいろいろトライしてみます。 ありがとうございます。
momura
ご指導いただいた皆様
いまさらですが、本件、DMAとpthreadを組み合わせると
高速化の効果があることが判りました。
SPI読み込み+DMA転送をひとつのスレッドにして、
その空き時間にメインにて他の処理(USBメモリ保存)をすることによって、
スレッドを使わないときと比べると1.5倍くらい速くなりました。
ご指導いただいた方々、ありがとうございました。
いまさらですが、御礼申し上げます。
> ということは、やり方次第で、DMAをうまく利用して処理速度を上げることは可能ということですね。
> 承知しました。 私もいろいろトライしてみます。 ありがとうございます。
shkoga
こんにちは。サムシングプレシャスの古賀と申します。
大村さん:
>②SPIにて外部から受信し、30Mbpsの速度が出ていることは確認できました。
> 添付画像はそのときのSCLK端子の波形です。1回あたり7バイトのデータを連続して読込んでおりますが、
> 各回の間に60μs近い間隔が空いてしまい、高速化できません。
> この間隔時間を短くする方法はないでしょうか? おそらくユーザーランドだけでは無理だと思われますが、
> 方法をご指導お願い申し上げます。
ご提示頂いたコードを拝見したところ、7Byte の送受信を行う ioctl() を繰り返し行なうようになっていますので、ioctl() 呼び出しのオーバーヘッドが、間隔の開く要因ではないかと思います。となると、3年ほど前の、Armadillo-420 に関する、このスレッドが参考になるかも知れません:
https://users.atmark-techno.com/comment/1417#comment-1417
momura
古賀様
お世話になります。 大村です。
返答拝見しました。
すみませんが、お教えください。
> ご提示頂いたコードを拝見したところ、7Byte の送受信を行う ioctl() を繰り返し行なうようになっていますので、ioctl() 呼び出しのオーバーヘッドが、間隔の開く要因ではないかと思います。
→私もそう思います。
>となると、3年ほど前の、Armadillo-420 に関する、このスレッドが参考になるかも知れません:
> https://users.atmark-techno.com/comment/1417#comment-1417
→こちらのスレッドを拝見しましたが、8バイト以上の場合は問題になるようですが、
今回の場合、7バイトですので、問題にならないような気がします。
SPI_IOC_MESSAGE()の扱いについて注意が必要な記述はありますが、
すみません、この関数の使い方はどこを見れば分かるでしょうか?
ご教示をお願い致します。
shkoga
こんにちは。サムシングプレシャスの古賀です。
大村さん:
>すみませんが、お教えください。
>
>>ご提示頂いたコードを拝見したところ、7Byte の送受信を行う ioctl() を繰り返し行なうようになっていますので、ioctl() 呼び出しのオーバーヘッドが、間隔の開く要因ではないかと思います。
>→私もそう思います。
>
>>となると、3年ほど前の、Armadillo-420 に関する、このスレッドが参考になるかも知れません:
>> https://users.atmark-techno.com/comment/1417#comment-1417
> →こちらのスレッドを拝見しましたが、8バイト以上の場合は問題になるようですが、
>今回の場合、7バイトですので、問題にならないような気がします。
確認ですが、お使いになっている SPI 対向デバイスは、どういう通信仕様なのでしょうか?
ご提示頂いたコードを見ると、FPGA のような雰囲気ですが、その通信仕様次第で高速化の余地があるかどうかは変わります。場合によっては、Linux は使わず、RTOS を使うなりベアメタルで実装するなりしないと、お望みの高速化は達席できないかも知れません。
先のコメントで紹介したスレッドでは、SPI 通信の間には、どうしても時間が空いてしまうので、一回の SPI 通信で転送するバイト数を増やすことにより、SPI 通信の間の空き時間の割合を減らすことで高速化を図る、ということが議論されています。お使いの SPI 対向デバイスが、7バイトより大きなサイズの転送を一度に行なえるのであれば、その方策(SPI 通信一回あたりの転送バイト数を増やすことで、SPI 通信の間の空き時間の影響を減らす)が有効でしょう。
しかし、お使いの SPI 対向デバイスが、一回の SPI 通信では7バイトしか転送できず、それを繰り返し行う際に、合計時間を短くしたい(SPI 通信の間の空き時間を短くしたい)、ということであれば、別の方策が必要です。
ところで、
>SPI_IOC_MESSAGE()の扱いについて注意が必要な記述はありますが、
>すみません、この関数の使い方はどこを見れば分かるでしょうか?
>ご教示をお願い致します。
Linux の spidev.h のコメントをご覧下さい:
https://github.com/spotify/linux/blob/master/include/linux/spi/spidev.h
その他ですと、このあたりが参考になりそうです:
https://qiita.com/eggman/items/7d0b35c3ed86e8983a50
http://brew-j2me.blogspot.jp/2010/05/linux-accessing-spi-bus-from-user-…
僕自身は、これを使ったことがないので間違っているかも知れませんが、SPI_IOC_MESSAGE() の引数は、spi_ioc_transfer 構造体の配列を ioctl() に渡す際の、配列の要素数を指定するようです。つまり、複数の SPI 通信を一回の ioctl() で SPI ドライバに行なわせたい場合には、一度に実行する SPI 通信の回数に等しい要素数の spi_ioc_transfer 構造体を用意して、その要素数を SPI_IOC_MESSAGE() に渡す、ということのようですね。
そうすれば、ioctl() の呼び出し回数を減らせますから、SPI 通信の間の空き時間を減らせる可能性があります。お使いの SPI 対向デバイスが、一回の SPI 通信では7バイトまでしか転送できないのであれば、こちらの方策(一回の ioctl() で複数回の SPI 通信を実行する)が解になるかと思います。
いかがでしょうか?
momura
古賀様
出張で回答が遅くなりました。
詳しい解説有り難う御座います。
> 確認ですが、お使いになっている SPI 対向デバイスは、どういう通信仕様なのでしょうか?
> ご提示頂いたコードを見ると、FPGA のような雰囲気ですが、その通信仕様次第で高速化の余地があるかどうかは変わります。場合によっては、Linux は使わず、RTOS を使うなりベアメタルで実装するなりしないと、お望みの高速化は達席できないかも知れません。
→仰るとおり対向はFPGAです。
> 先のコメントで紹介したスレッドでは、SPI 通信の間には、どうしても時間が空いてしまうので、一回の SPI 通信で転送するバイト数を増やすことにより、SPI 通信の間の空き時間の割合を減らすことで高速化を図る、ということが議論されています。お使いの SPI 対向デバイスが、7バイトより大きなサイズの転送を一度に行なえるのであれば、その方策(SPI 通信一回あたりの転送バイト数を増やすことで、SPI 通信の間の空き時間の影響を減らす)が有効でしょう。
>
仰る意味はよく分かります。どうしようもなければ、そのようにバースト転送的な処理にするしかないと考えていますが、
FPGA側も、armadilllo側も処理が煩雑になるため、できれば避けたいと思っておりました。
> >SPI_IOC_MESSAGE()の扱いについて注意が必要な記述はありますが、
> >すみません、この関数の使い方はどこを見れば分かるでしょうか?
> >ご教示をお願い致します。
>
> Linux の spidev.h のコメントをご覧下さい:
> https://github.com/spotify/linux/blob/master/include/linux/spi/spidev.h
>
> その他ですと、このあたりが参考になりそうです:
> https://qiita.com/eggman/items/7d0b35c3ed86e8983a50
> http://brew-j2me.blogspot.jp/2010/05/linux-accessing-spi-bus-from-user-…
>
> 僕自身は、これを使ったことがないので間違っているかも知れませんが、SPI_IOC_MESSAGE() の引数は、spi_ioc_transfer 構造体の配列を ioctl() に渡す際の、配列の要素数を指定するようです。つまり、複数の SPI 通信を一回の ioctl() で SPI ドライバに行なわせたい場合には、一度に実行する SPI 通信の回数に等しい要素数の spi_ioc_transfer 構造体を用意して、その要素数を SPI_IOC_MESSAGE() に渡す、ということのようですね。
> そうすれば、ioctl() の呼び出し回数を減らせますから、SPI 通信の間の空き時間を減らせる可能性があります。お使いの SPI 対向デバイスが、一回の SPI 通信では7バイトまでしか転送できないのであれば、こちらの方策(一回の ioctl() で複数回の SPI 通信を実行する)が解になるかと思います。
>
> いかがでしょうか?
→詳しい解説ありがとうございます。 大変参考になりました。まずはこれにトライしてみます。
御礼申し上げます。 また分からないことがあったらよろしくお願い申し上げます。
y.nakamura
中村です。
古賀さんや溝渕さんがほとんど書いてくれていますが、
SPIのDMA速度の確認方法の具体例です。
SPIのマスタはスレーブがなくても動きますから、
速度を確認したいだけなら相手(スレーブ)はつながずに、
> uint8_t tx[7] = {0, }; //ここを変更すると取り込みデータ数が変わる
> uint8_t rx[7] = {0, };
を
uint8_t tx[1024] = {0, };
uint8_t rx[1024] = {0, };
のような大きな配列にしてみるとか、
参考:https://armadillo.atmark-techno.com/forum/armadillo/1178#comment-5394
あるいはSPI_IOC_MESSAGE(N)のNを増やして
struct spi_ioc_transfer tr[256];
....
ioctl(fd_spi, SPI_IOC_MESSAGE(256), tr);
のようにして試してみてはどうでしょうか?
もっと大きな数の方がいいかもしれません。
--
なかむら
momura
中村様
返信ありがとうございます。
> SPIのマスタはスレーブがなくても動きますから、
> 速度を確認したいだけなら相手(スレーブ)はつながずに、
>
> > uint8_t tx[7] = {0, }; //ここを変更すると取り込みデータ数が変わる
> > uint8_t rx[7] = {0, };
> を
> uint8_t tx[1024] = {0, };
> uint8_t rx[1024] = {0, };
> のような大きな配列にしてみるとか、
> 参考:https://armadillo.atmark-techno.com/forum/armadillo/1178#comment-5394
>
> あるいはSPI_IOC_MESSAGE(N)のNを増やして
> struct spi_ioc_transfer tr[256];
> ....
> ioctl(fd_spi, SPI_IOC_MESSAGE(256), tr);
> のようにして試してみてはどうでしょうか?
> もっと大きな数の方がいいかもしれません。
→
より手っ取り早く、速度の確認ができそうですね。
試してみます。
御礼申し上げます。
momura
大村です。
皆様、いろいろありがとうございました。
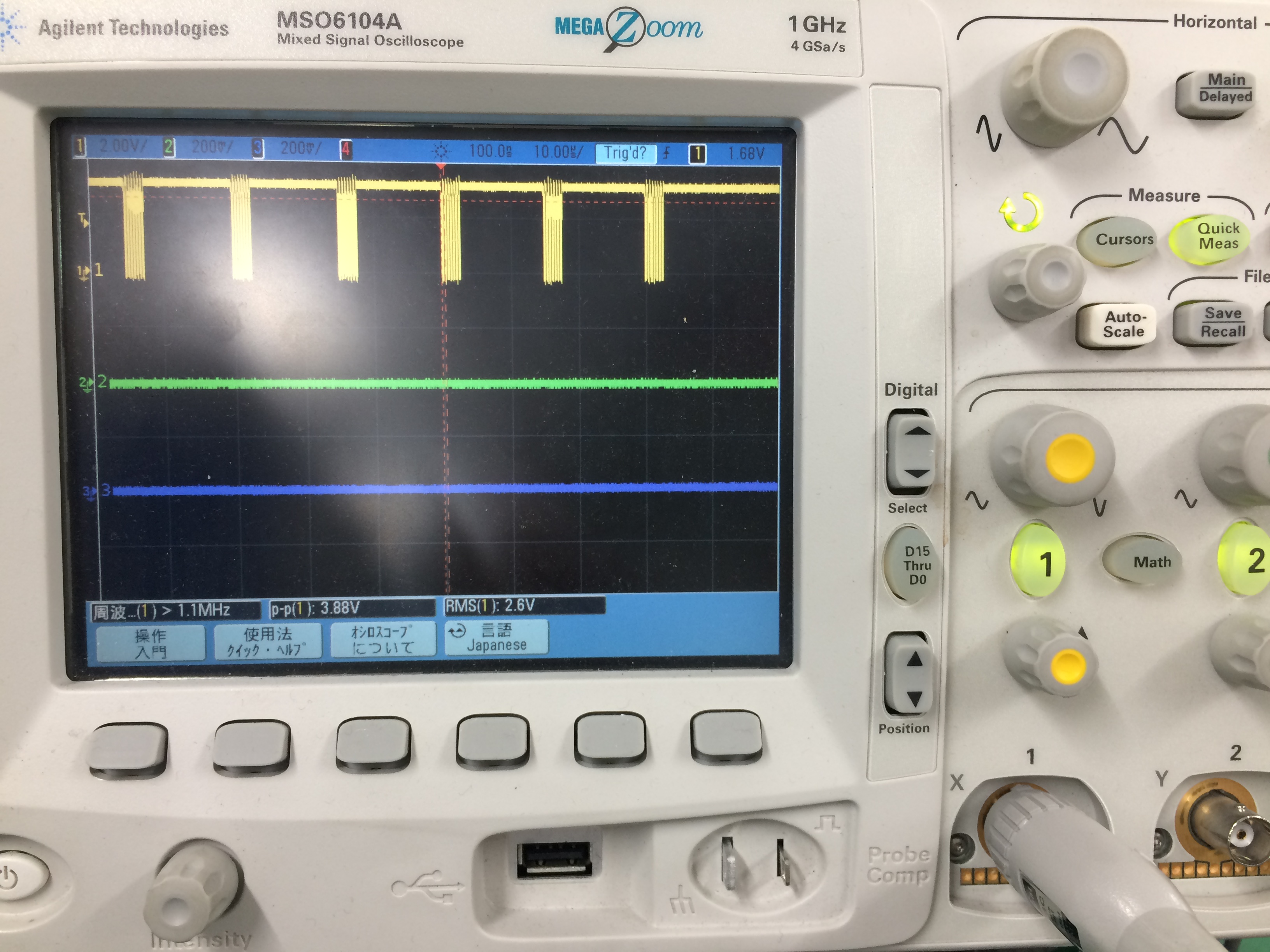
いろいろ試してみました。SPI_IOC_MESSAGE(N)のNを増やしてみましたが、
添付、SCLK波形のように、改善はされるものの各回の間に10数μsの間隔が入ってきます。
結果、覚悟を決めてバースト転送することに決めました。 uint8_t tx[1024] = {0, }; のように。
それが最も高速化できそうです。OSがリアルタイムOSではないので、こんなこともあるのですね。
今回は勉強になりました。また、皆様のご親切さに感謝致します。本当にありがとうございました。
| ファイル | ファイルの説明 |
|---|---|
| 2018-04-24 11.53.35.jpg |
{kind=link}
y.nakamura
中村です。
> いろいろ試してみました。SPI_IOC_MESSAGE(N)のNを増やしてみましたが、
> 添付、SCLK波形のように、改善はされるものの各回の間に10数μsの間隔が入ってきます。
先日の投稿ではあえて書きませんでしたが、予想通りです。
SPI_IOC_MESSAGE(N)の場合、Nの1回毎にDMAの[設定/スタート]と
[完了の割り込み待ち]をしていて、1回ごとのこの処理に
時間がかかっているのだと思います。
> 結果、覚悟を決めてバースト転送することに決めました。 uint8_t tx[1024] = {0, }; のように。
相手が対応できるなら、これがいいようですね。
--
なかむら
y.nakamura
中村です。
解決してますが、追加です。
> SPI_IOC_MESSAGE(N)の場合、Nの1回毎にDMAの[設定/スタート]と
> [完了の割り込み待ち]をしていて、1回ごとのこの処理に
> 時間がかかっているのだと思います。
DMA完了の割り込み待ちに結構時間がかかっていそうです。
もしかしたらSPI_IOC_MESSAGE(N)で、今回ように1回の
転送データが少ない場合、DMAを使わな方が早いかも、です。
uint8_t tx[1024]が使えればそれで終わりでいいと思いますが、
どうなるか試してみてはどうでしょう?
--
なかむら
momura
中村様
返答ありがとうございます。
> > SPI_IOC_MESSAGE(N)の場合、Nの1回毎にDMAの[設定/スタート]と
> > [完了の割り込み待ち]をしていて、1回ごとのこの処理に
> > 時間がかかっているのだと思います。
>
> DMA完了の割り込み待ちに結構時間がかかっていそうです。
> もしかしたらSPI_IOC_MESSAGE(N)で、今回ように1回の
> 転送データが少ない場合、DMAを使わな方が早いかも、です。
>
> uint8_t tx[1024]が使えればそれで終わりでいいと思いますが、
> どうなるか試してみてはどうでしょう?
ご指導いただいた点、試してみます。
ありがとうございます。
at_mizo
2018年4月19日 11時45分
溝渕です。
> DMA転送が開始されるだろうということは判りました。(もしこの理解が間違っていたらご指摘ください)
> dmas = <&sdma 6 7 1>, <&sdma 7 7 2> /* ADD */
> dma-names = "rx", "tx" /* ADD */
合っています。i.MX 7Dリファレンスマニュアル(i.MX 7Dual Applications
Processor Reference Manual)の"Table 7-3. SDMA event mapping"に記載の通
り、SDMAのIDに誤りはありません。
> この後の手順がよく分かりません。ユーザーランドのアプリケーションで、DMA転送されたメモリ上のデータ
> は何処を参照して、使用すればよいのか、ご指導をお願い致します。
まず、DMAは、ECSPIのFIFOとメモリ間で行なわれます。DMAを利用しない場合
は、FIFOアクセスはCPUが行います。そのため、DMAしてもしなくてもユーザー
ランドからのアクセス方法にも違いはありません。
https://users.atmark-techno.com/blog/615/2577
で紹介されている「Armadillo実践開発ガイド第3部」では、SPIデバイスファ
イルに対するioctl(2)実行で読み出しを行っています。
> サンプルソフトのようなものがあれば有り難く、何卒よろしくお願い申し上げます。
SPIDEVの利用方法については、Linuxカーネルソースに含まれる以下の資料が参考になるかと思います。
Documentation/spi/spidev
ioctl(2)コマンドの利用例は、以下のサイトで"SPI_IOC_MESSAGE"等と検索す
ると見付かると思います。
https://codesearch.debian.net/
> 添付画像はそのときのSCLK端子の波形です。1回あたり7バイトのデータを連続して読込んでおりますが、
> 各回の間に60μs近い間隔が空いてしまい、高速化できません。
データの読込みはどのように行っていますか。